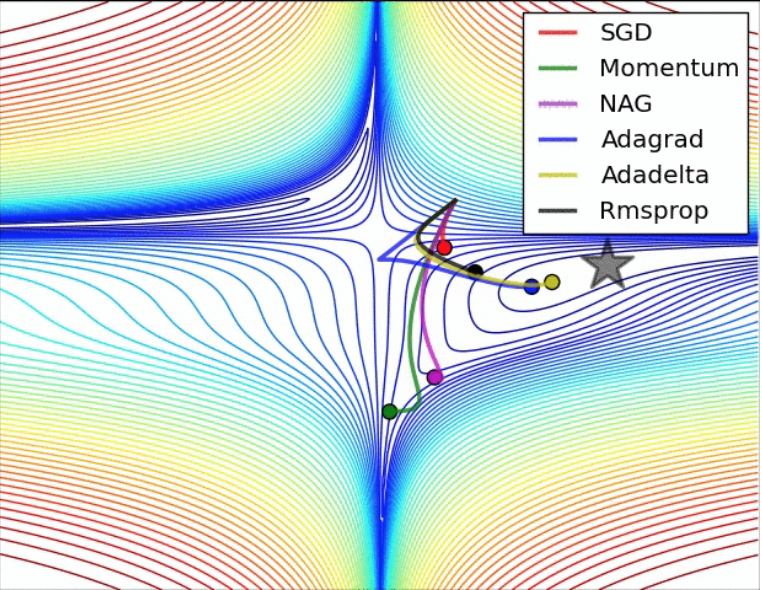
深度学习常见优化算法总结
简单总结下常见的一阶优化算法,本文约定符号如下: 为在mini-batch数据上求得的梯度,
为模型参数,
为学习率。
SGD
最基本的方法,只用到当前时刻的梯度信息,每次都沿着当前的梯度下降方向往前走一小步。SGD有几个主要的问题:
- 学习率和学习率衰减方案对结果影响非常大,调起来麻烦
- 由于梯度方向往往不是指向最优解的(想象下椭圆形的梯度等高线),一般而言,我们希望梯度大的方向步子能小一点,梯度小的方向步子大一点,这样收敛会快,但是SGD每个方向学习率是一样的,所以下降方向容易震荡,导致收敛慢
- 容易陷入局部最优和鞍点
SGD with momentum
带动量的SGD,不仅会利用当前时刻的梯度,同时会用到历史梯度信息,相当于把历史梯度信息按指数衰减进行加权平均,最后的效果就是加了“惯性”,梯度较大但是来回震荡的方向会互相抵消,梯度较小但是一直保持一致方向的会不断累积,这样可以避免下降方向来回震荡从而加速收敛(如下图所示),也有利于逃出鞍点。
 SGD without momentum
SGD without momentum
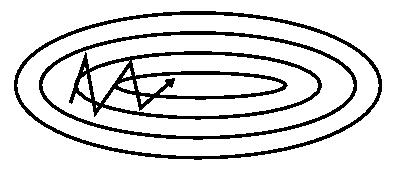 SGD with momentum
SGD with momentum
SGD with Nesterov momentum
改进版的带动量的SGD,不同之处在于梯度的计算,梯度不是基于当前位置计算的,而是先按动量试探下一步的大概位置,然后估计梯度,其他步骤一样,这样做的好处是可以提前纠正动量方向的偏差。
AdaGrad
自适应梯度,记录每一步的梯度平方和,用来调节不同参数的学习率,达到自适应学习率调节的目的。对于频繁更新的参数,学习率会越来越小,反之亦然。对于稀疏特征比较友好,比如训练词向量的时候可以试试。另一方面,由于可以自适应学习率,其实也可以减少震荡,因为震荡幅度大的话,累加的调节系数会越来越大,从而使震荡方向学习率降下来。虽然AdaGrad在凸优化上有一些比较好的性质,但是训练深度神经网络时,学习率容易在一开始就下降得过快导致效果不佳。
RMSProp
全称Root Mean Square Prop,Hinton老爷子提出来的,这是一种没有正式文献发表但是在各大开源库中都有实现的方法。。RMSProp在AdaGrad的基础上加了指数衰减来缓解学习率下降过快的问题,在大部分问题上效果都不错。RMSProp当然也可以加动量项。
Adam
全称adaptive momentum,另一种自适应学习率的方法,和RMSProp的不同主要有两点,一方面,不直接使用当前梯度,而是使用历史加权平均梯度;另一方面,对加权后的一阶动量和二阶动量都做校正,相当于得到一个无偏估计,不像RMSProp在早期的时候bias会比较大。Adam的超参数也比较好调,大部分时候用默认参数就行。但是,ICLR2018爆出Adam的收敛性证明有问题,而且给出了实锤counter example,在一些简单的问题上没法收敛到最优解,作者提出了一种fix的方法AMSGrad,但是实测效果好像和Adam差不多,但这不影响文章拿了best paper。ICLR2019最近放出的文章里,又有一篇是讲Adam的,貌似又提出了一种新的方法叫AdaShift,不知道效果咋样。。坐等各路大神测试。。
总结
优化方向是个大坑,这里主要总结神经网络mini-batch优化的时候常见的方法,并重点分析了其中的思路。其实本质还是利用梯度信息做一阶优化,主要围绕着SGD的问题做改进,比如说怎么减少震荡,怎么自适应学习率,所以就有了各种花式优化器。但是最后的问题是,我们炼丹的时候该选哪种呢?这个也要看具体应用,但一般没时间调的话就试试默认参数的RMSProp和Adam,一般效果不会太差,有时间的话可以仔细调调带动量的SGD,说不定会有惊喜。
经验总结
现在用的最多的算法是SGD和Adam,两者各有好坏。SGD能够到达全局最优解,而且训练的最佳精度也要高于其他优化算法,但它对学习率的调节要求非常严格,而且容易停在鞍点;Adam很容易的跳过鞍点,而且不需要人为的干预学习率的调节,但是它很容易在局部最小值处震荡,存在在特殊的数据集下出现学习率突然上升,造成不收敛的情况。
| 算法 | 优点 | 缺点 | 适用情况 |
|---|---|---|---|
| BGD | 目标函数为凸函数时,可以找到全局最优值 | 收敛速度慢,需要用到全部数据,内存消耗大 | 不适用于大数据集,不能在线更新模型 |
| SGD | 避免冗余数据的干扰,收敛速度加快,能够在线学习 | 更新值的方差较大,收敛过程会产生波动,可能落入极小值(卡在鞍点),选择合适的学习率比较困难(需要不断减小学习率) | 适用于需要在线更新的模型,适用于大规模训练样本情况 |
| Momentum | 能够在相关方向加速SGD,抑制振荡,从而加快收敛 | 需要人工设定学习率 | 适用于有可靠的初始化参数 |
| Adagrad | 实现学习率的自动更改 | 仍依赖于人工设置一个全局学习率,学习率设置过大,对梯度的调节太大。中后期,梯度接近于0,使得训练提前结束 | 需要快速收敛,训练复杂网络时;适合处理稀疏梯度 |
| Adadelta | 不需要预设一个默认学习率,训练初中期,加速效果不错,很快,可以避免参数更新时两边单位不统一的问题 | 在局部最小值附近震荡,可能不收敛 | 需要快速收敛,训练复杂网络时 |
| Adam | 速度快,对内存需求较小,为不同的参数计算不同的自适应学习率 | 在局部最小值附近震荡,可能不收敛 | 需要快速收敛,训练复杂网络时;善于处理稀疏梯度和处理非平稳目标的优点,也适用于大多非凸优化,适用于大数据集和高维空间 |
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- 如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
- 在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果