XMem: 基于Atkinson-Shiffrin记忆模型的长时视频对象分割
Cheng H K, Schwing A G. XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model[C]//Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVIII. Cham: Springer Nature Switzerland, 2022: 640-658.
Abstract
XMem:是一种用于长时视频的视频对象分割框架,受Atkinson-Shiffrin记忆模型的启发,具有统一的特征记忆存储能力。先前,关于视频对象分割的工作通常只使用一种类型的特征记忆。对于超过一分钟的视频,单一功能的记忆模型将记忆消耗和准确性紧密绑定在一起。与此相反,我们基于Atkinson-Shiffrin模型开发了一个包含多个独立且深度连接的特征记忆存储框架,该架构包括:一个快速更新的感官记忆、一个高分辨率的工作记忆和一个紧凑并且持续的长时记忆。其中的关键是,我们开发了一个记忆增强算法,该算法可以周期性地将活跃使用的工作记忆元素整合到长时记忆中,从而避免了记忆爆炸,并且最大限度地减少了长时预测中的性能衰减。结合这种新的内存读取机制,XMem在长时视频数据集上极大地超越了当前最先进技术的性能。同时在短视频数据集中与最先进的方法不相上下。
Ch01 介绍
视频对象分割(Video Object Segmentation,VOS):在给定视频中用颜色突出指定的目标对象。在这里,我们专注于半监督场景,其中第一帧注释由用户提供,并且该方法尽可能准确地分割所有其他帧中的对象,同时侧重于长时视频处理条件下运行状态的实时性、在线能力和较小的内存占用。
由于信息必须从给定注释的视频帧传播到其他视频帧,大多数VOS方法使用特征记忆存储与对象相关的深度网络表示。在线学习方法[^3][^49][^42]使用网络权重来记忆特征,这种方法需要测试阶段的训练,从而降低了预测的速度。递归方法则通过掩码[^39]或者隐表示[^20][^47]来传播最近帧的信息,但是这类方法容易出现信息漂移,并且难以解决遮挡问题。
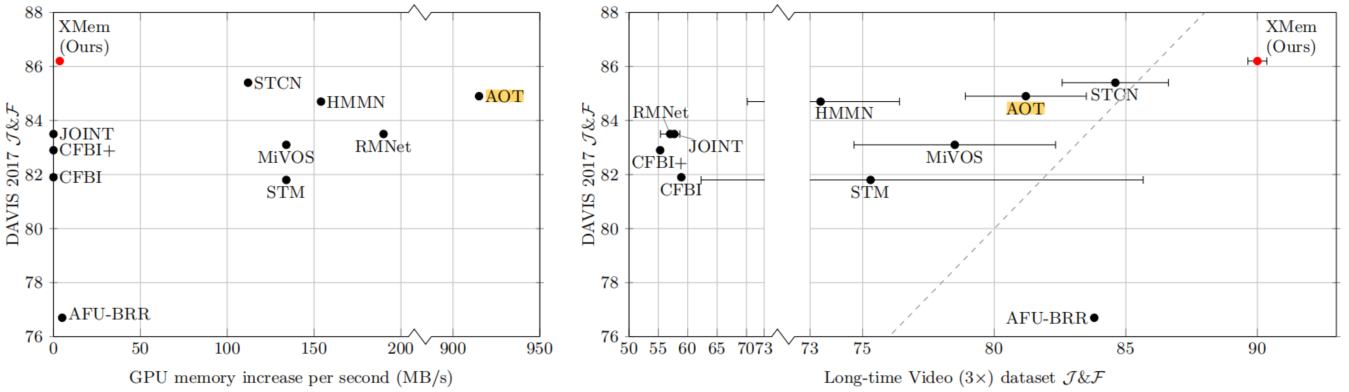
图1 最先进的VOS算法的缩放状态?左图:适时分割质量的内存缩放;右图:从标准的短时视频(Y轴)到长时视频(X轴)的分割质量缩放,其中虚线表示1:1的性能比。误差线表示适用条件下记忆采样的标准偏差。详见(Sec4.1)
近来最先进的VOS方法使用注意力机制[^36][^18][^54][^9][^60]将存储在特征记忆中的过去帧的表示与从亲近观察到的需要分割的查询帧中提取的特征联系起来。尽管这些方法的性能不错,但是它们都需要大量的GPU内存来存储过去帧的表示,因此在实践中也就很难在消费级硬件上处理超过一分钟的视频。
当今也存在专门为长时视频设计的VOS方法[^29][^27],但是它们多会牺牲了分割质量。具体地说,这些方法在特征记忆插入时通过合并已经存储在特征记忆中的旧特征与提取出来的新特征从而减少了表示的大小。由于高分辨率特征被当场压缩,这些方法出现了少量的分割精度上的损失。图1展示了短时/长时视频数据集中GPU内存消耗和分割质量之间的关系,详见(Sec4.1)。
我们认为模型性能和GPU内存消耗之间的联系是使用单一特征记忆造成的,因此为了解决这种限制,我们提出了一种统一的内存结构,称为XMem。受到atkinson-shiffrin记忆模型[^1]的启发,该模型假设人类的记忆由三个部分组成,XMem也保持了三个独立并且深度连接的特征记忆存储:一个快速更新的感官记忆、一个高分辨率的工作记忆和一个紧凑并且持续的长时记忆。在XMem中,感官记忆对应着GRU[^11]的隐式表示,其每帧更新一次,提供了时间上的平滑性,但是由于表示漂移而无法执行长时预测。作为补充,工作记忆是从历史帧的子集中聚集起来的,并且平等地考虑每帧的影响从而避免了时间上的漂移。为了控制工作记忆的内存消耗,受人类记忆中整合机制的启发[^46],XMem周期性地将其表示整合到长时记忆中。为了满足XMem将长期记忆存储为一组高度紧凑的原型,我们开发了一种记忆增强算法,将更加丰富的信息聚合到这些原型中,以防止由于子采样而导致的量化噪声。我们设计了一套时空记忆读取机制用于从工作记忆和长时记忆中读取信息。混合了三种特征记忆存储使得算法既允许以高精度处理长时视频,还能保持较低的GPU内存消耗。
我们发现XMem在长时视频数据集[^29]上极大地超越了当前最先进的实验结果,更重要的是XMem在短时视频数据集上[^41][^57]也与当前最先进的实验结果不相上下。综上所述:
- 我们设计了XMem。受Atkinson-Shiffrin记忆模型[^1]的启发,我们引入了具有不同时间尺度的记忆存储,并且为它们配备了记忆读取操作,满足长时视频和短时视频上的高质量视频对象分割的需要。
- 我们开发了一种从工作记忆中选择表示原型的记忆整合算法,以及一种为长时记忆存储的需要将这些原型充实为紧凑的而且强大的表示的记忆增强算法。
Ch02 相关工作
一般的VOS方法
大多数VOS方法使用特征记忆来存储第一帧中给出的信息,和分割其他新的帧。在线学习方法在测试阶段依然训练或者微调它们的网络,因此在通常情况下会减慢推理速度[^3][^49][^32]。最近的改进成交显著[^34][^42][^37][^2],但是它们仍然需要在线适应,这种适应对输入数据是敏感的,并且随着训练数据的增多,改进的收益也会慢慢失去。相比而言,基于跟踪的方法[^39][^52][^10][^22][^5][^35][^63][^19][^47][^20][^56]执行的是帧到帧的传播,因此在测试阶段依然有效,但是它们缺少长时上下文,并且在对象遮挡时经常会失去跟踪。虽然有些方法[^48][^59][^53][^23][^26][^6]会保留第一参考帧 用于全局匹配,但是受限于长时上下文的缺失,随着时间跨度增大,匹配变得更加困难。为了解决上下文限制,当前最先进的方法使用更多的过去帧作为特征记忆[^36][^13][^64][^21][^28][^58][^16]。特别是,时空记忆网络(Space-Time Memory,STM)[^36]的流行,以及其后的许多工作[^43][^8][^18][^54][^50][^31][^9][^44][^33]。在这些扩展中,由于STCN[^9]的简单有效,我们将其作为我们的工作记忆的主干。然而,因为STM的不断增长的特征记忆库,许多变体无法处理长时视频。AOT[^60]是最近的一项工作,它将注意力机制扩展到了转换器,但仍然没有解决GPU内存爆炸问题。一些方法[^33][^14]使用局部特征记忆,但是它们没有考虑容器外的长时上下文。相比而言,XMem使用多个记忆存储去捕捉不同的时间上下文,同时得益于我们的长时记忆和整合使得GPU内存的使用受到了严格地限制。
专门处理长时视频的方法
Liang等人[^29]提出了AFB-URR方法,该方法选择性地使用指数移动平均值将给定的记忆元素与现有的靠得很近的记忆元素合并,或者将其添加为一个新的元素。当特征记忆达到预先设定的限制时,基于最少使用机制来去除未使用的特征。Li等人[^27]提出了一种全局上下文模块,它平均了所有过去的记忆到一个单一的表示中,从而保证GPU内存的增长不再随时间改变。然而,这两种方法都过早地将新来的高分辨率特征记忆压缩成一个紧凑的表示,从而牺牲了分割的精度。我们提出的多存储特征记忆则避免了这种过早地压缩,并且在短时和长时预测中实现了更高的准确性。
Ch03 XMem
Sec3.1 概述
图2提供了XMem的概述。为了读者理解,我们采用的是单目标对象,但是XMem本身是为多目标对象设计的。给定第一帧 (图2左上角)的图像和目标对象掩码,XMem跟踪对象并且为后续查询帧生成相应的掩码。为此,我们首先使用输入数据来初始化不同的特征记忆存储。对于每个后续的查询帧 ,我们分别从长期记(Sec3.3)、工作记忆(Sec3.4)和感官记忆(Sec3.5)中进行记忆读取(Sec3.2)。读出的特征用于生成分割掩膜。然后,我们以不同的频率更新每个特征记忆存储:每帧更新感官记忆、每$r$帧在工作记忆中插入特征。当工作记忆达到预先定义的最大帧数$T_{\max}$,就以高度紧凑的形式将工作记忆中的特征融合到长期记忆中。当长期记忆也要溢出时(这仅会发生在处理上千帧以后),抛弃过时的特征从而限制GPU内存的最大使用量。这些特征记忆存储的协同工作,即使对于很长的视频,也能以低GPU内存使用率提供高质量的功能。
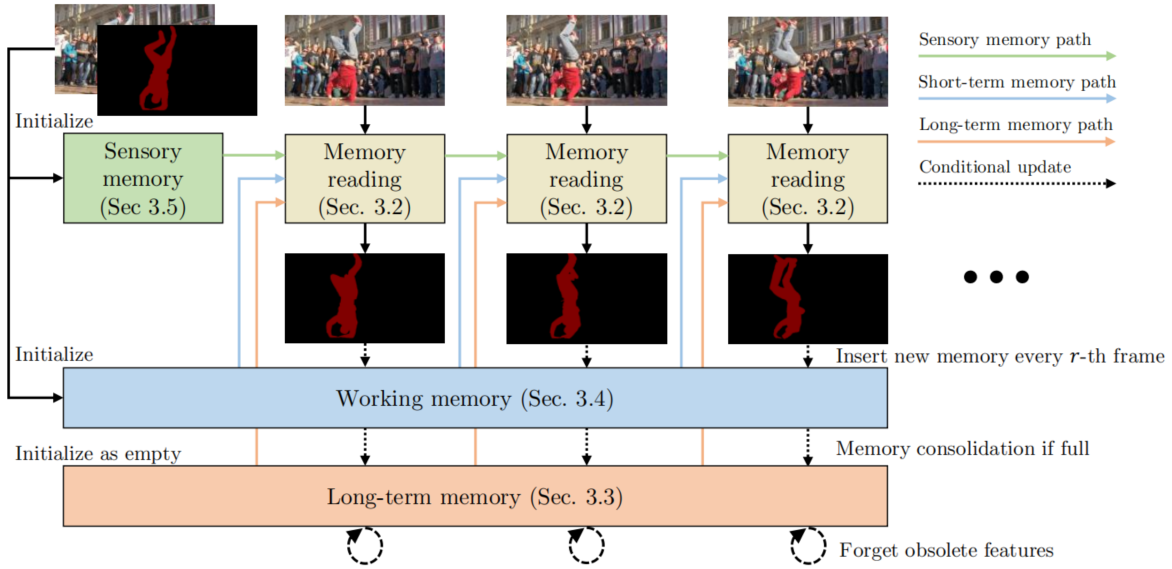
图2. XMem的概述。记忆读取操作从全部三个记忆存储中提取相关特征,并且使用这些特征来产生掩膜。为了融合新的记忆,感官记忆每帧更新一次,而工作记忆每;$r$帧更新一次。当工作记忆被填满时,它将以紧凑的形式融合到长期记忆中,随着时间的推移,长时记忆会忘记过时的特征。
XMem由三个端到端的可训练的卷积网络组成(见图3):一个提取特定查询图像特征的查询编码器、一个获取记忆读取步骤的输出以生成对象掩膜的解码器,以及一个将图像与对象掩码混合以提取新的记忆特征的值编码器,这些网络的细节参见(Sec3.6)。在下文中,我们将首先介绍记忆读取操作,然后再详细讨论每个特征记忆存储。
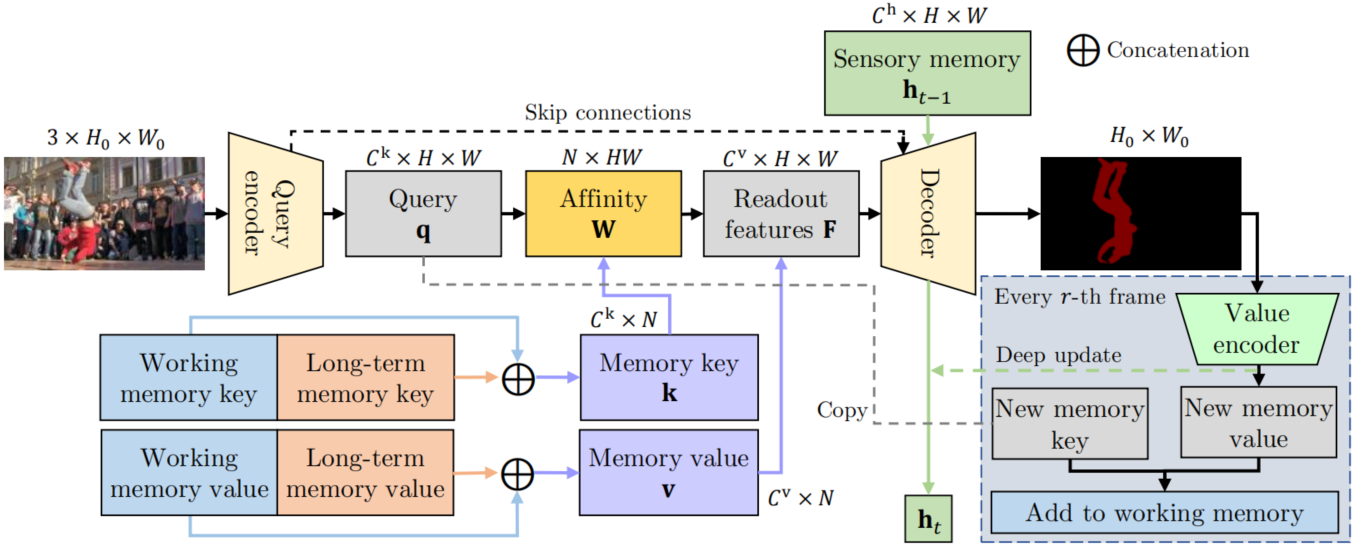
图3. 对单个帧执行记忆读取和掩膜解码的过程。从图像中提取查询$\mathbf{q}$,并且基于注意力从工作记忆和长时记忆中执行记忆读取获得特征$\mathbf{F}$,再与感官记忆一起送入到解码器去生成掩膜。对于每$r$帧,我们将新特征存储到工作记忆中,并对感官记忆执行一次深度更新。
Sec3.2 记忆读取(Memory Reading)
图3描述了单个帧的记忆读取和掩膜生成过程。掩膜是通过解码器计算的,解码器使用短时感官记忆$\mathbf{h}_{t-1}\in\mathbb{R}^{C^h\times H\times W}$和存储在长时记忆与工作记忆中的表示信息的特征$\mathbf{F}\in\mathbb{R}^{C^v\times H\times W}$。特征通过读出操作计算:
$$
\mathbf{F=vW(k,q)}
$$
其中,$\mathbf{k}\in\mathbb{R}^{C^k\times N}$和$\mathbf{v}\in\mathbb{R}^{C^v\times N}$是共$N$个元素的$C^k$维键(key)和$C^v$维的值(value),而且$\mathbf{W(k,q)}$是大小为$N\times HW$的关联矩阵,用于表示读出操作,这种读出操作是由键$\mathbf{k}$和查询$\mathbf{q}\in\mathbb{R}^{C^k\times HW}$控制,而查询是通过查询帧从查询编码器中获得。读出操作将每个查询元素映射到所有$N$个记忆元素构成的分布,并且相应地聚合它们的值$\mathbf{v}$。
关联矩阵$\mathbf{W(k,q)}$是通过在相似度矩阵$\mathbf{S(k,q)}$的记忆维度(行)上应用 $\text{softmax()}$函数获得,相似度矩阵$\mathbf{S(k,q)}$包含了成对的每个键元素和每个查询元素的相似度信息。为了计算相似度矩阵,我们注意到STCN[^9]中提出了L2相似度比点积[^36]更加稳定,但是表现力相对较弱(如:不能编码记忆元素的置信度水平)。为了解决这个问题,我们通过引入两个新的缩放项提出了新的相似度函数(各向异性L2,anisotropic L2),这两个缩放项打破了键和查询之间的对称性,可视化效果参见图4。
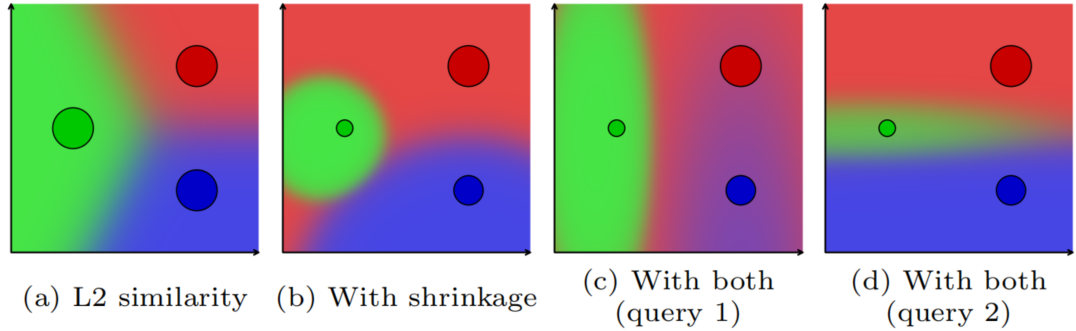
图4. 2D中相似度函数的可视化效果,背景颜色展示了每个记忆元素(RGB)的影响。L2相似性[^9](图4a)均匀地考虑了所有的存储元素;收缩项(图4b)允许编码元素级别的置信度(通过点的大小可视化),该置信度考虑了混合权重的影响区域和锐度。选择项允许记忆关于特定查询的解释,(图4c)和(图4d)展示了分别关注垂直和水平两个维度的不同查询的效果。(图4b)可以看作选项项是各向同性的情况。当组合在一起后,我们可以对更加复杂的相似度关系进行建模。
具体来说,键与收缩项$\mathbf{s}\in[1,\infin)^N$相关联,查询与选择项$\mathbf{e}\in[0,1]^{C^k\times HW}$相关联。然后,第$i$个键元素与第$j$个查询元素之间的相似度的计算公式:
$$
\mathbf{S(k,q)}{ij}=-\mathbf{s}i\sum_c^{C^k}\mathbf{e}{cj}(\mathbf{k}{ci}-\mathbf{q}_{cj})^2
$$
当$\mathbf{s}i=\mathbf{e}{cj}=1,\forall i,\forall j,\forall c$,公式与原始的L2相似度[^9]等价。收缩项$\mathbf{s}$直接相似度,并且显式编码了置信度——高收缩度表示低置信度,并且导致了更加局部的影响效果。请注意,如果查询恰好与低置信度的键相一致,那么低置信度的键也能拥有大的贡献,从而避免了点积中存在的记忆主导问题(详细讨论参见[^9])。不同的是,选择项$\mathbf{e}$控制着键空间中每个通道(channel)相对重要性,使得注意力更多放在更易区分的通道上。
选择项$\mathbf{e}$与查询$\mathbf{q}$是由查询编码器一起生成的。缩放项$\mathbf{s}$与工作记忆和长时记忆中的键$\mathbf{k}$和值$\mathbf{v}$一起收集的。这个集合的简单实现就是在最后一个维度进行拼接:$\mathbf{k=k^w\oplus k^{lt}}$和$\mathbf{v=v^w\oplus v^{lt}}$,其中的上标分别表示工作记忆和长时记忆。工作记忆由键$\mathbf{k^w}\in\mathbb{R}^{C^k\times THW}$和值$\mathbf{v^w}\in\mathbb{R}^{C^v\times THW}$,其中$T$是工作记忆的帧数。长时记忆由键$\mathbf{k^{lt}}\in\mathbb{R}^{C^k\times L}$和值$\mathbf{v^{lt}}\in\mathbb{R}^{C^v\times L}$组成,其中$L$是长时记忆原型的数量。因此,工作记忆和长时记忆的元素总数是$N=THW+L$。
接下来,我们将详细讨论特征记忆存储。
Sec3.3 长时记忆(Long-Term Memory)
动机
长时记忆是处理长时视频的关键。为了存储一级紧凑的(GPU内存消耗少)但是具有表示性的(分割质量高)的记忆特征,我们设计了一个记忆整合过程。整个过程从工作记忆中选择原型,再用记忆增强算法来丰富特征,详见图5。
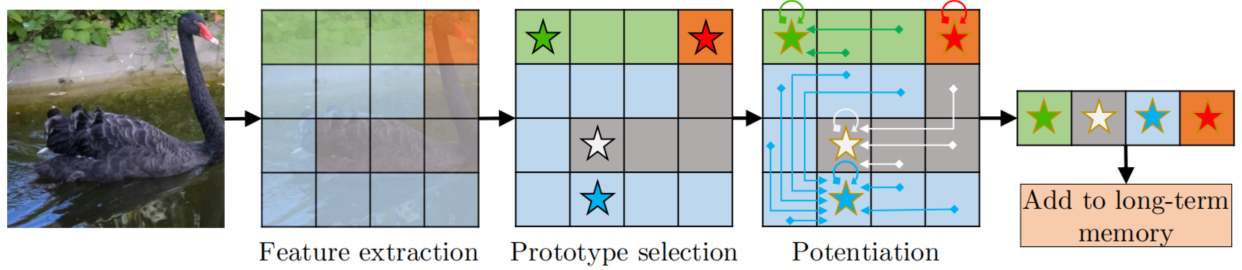
图5. 记忆整合过程。给定图片,提取特征作为记忆键(图像步幅加大)。用颜色将特征可视化。对于记忆整合,首先从候选(所有网格)中选取原型键(星型网格),然后从所有候选中调用增强(非局部聚合值)以生成更具有表示性的原型值(黄金轮廓)。获得的原型键与值被加入到长时记忆中。这里只展示了一帧——实际情况是一次合并将使用多个帧 。
当工作记忆达到预定义的大小$T_\max$时,系统执行记忆整合。第一帧(包含了用户提供的基准数据)和最近的$T_\min-1$记忆帧将会保存在工作记忆中作为一个高分辨率的缓存,而其余帧($T_\max-T_\min$帧)是转换为长时记忆表示的候选帧。这些候选的键与值分别记作$\mathbf{k^c\subset k^w}$和$\mathbf{v^c\subset v^w}$。后续,原型选择过程就是挑选一组紧凑的原始键$\mathbf{k^p\subset k^c}$,记忆整合算法生成与这些原型键相关的特征丰富的原型值$\mathbf{v^p}$。最后,这些原型键和值被添加到长时记忆$\mathbf{k^{lt}}$和$\mathbf{v^{lt}}$中。
原型选择
在这步中,从候选中采样一个小的表示子集$\mathbf{k^p\subset k^c}$作为原型。其本质是只挑选少量原型,因为它们的数量与产生的长时记忆的大小成正比。受人类记忆的启发,挑选高频使用的候选值,从而将频繁访问或者研究的模式放入长时记忆中。具体就是选择最常用的$P$个候选作为原型,记忆元素的使用频率基于关联矩阵$\mathbf{W}$(等式1)中的累积关联度(概率质量函数),并且基于每个候选在工作记忆中的持续时间执行归一化。需要注意的是,每个候选的持续时间至少是$r\cdot(T_\min-1)$,才能获得平移的使用频率统计数据。于是获得的这些原型的键作为$\mathbf{k^p}\in\mathbb{R}^{C^k\times P}$。
记忆增强
到目前为止,从候选键$\mathbf{k^c}$中采样的原型键$\mathbf{k^p}$是稀疏和离散的。如果以同样的方式对原型值$\mathbf{v^p}$执行采样,那么得到的原型将不可避免地代表其他候选,并且容易出现量化噪声。避免这个问题的常用技术是反量化噪声滤波器(如:高斯)[^15]。基于相似的动机,信号执行滤波,并且将更多的信息聚合到每个采样的原型中。虽然标准化的滤波可以很容易地在图像平面 (2D)或者时间体(3D)上执行,但是执行结果会导致特征模糊,尤其是在物体边界附近。为了缓解这个问题,我们转而在高维($C^k$)键空间中构造领域执行滤波,从而利用由键$\mathbf{k^p}$和$\mathbf{k^c}$给出的高维表示的邻接信息。由于这些键必须被计算和存储用于记忆读取,所以由此产生的运行时间和内存消耗也是值得的。
具体来讲,对于每个原型,我们通过加权平均来聚合来自所有候选值$\mathbf{v^c}$的值。在键的相似性上使用softmax计算权重。为此,我们顺便重用了(等式2)。通过使用候选键$\mathbf{k^c}$替换记忆键$\mathbf{k}$,使用原型键$\mathbf{k^p}$替换查询$\mathbf{q}$,我们获得了相似度矩阵$\mathbf{S(k^c,k^p)}$。如前所述,我们使用softmax获得了关联矩阵$\mathbf{W(k^c,k^p)}$(其中,每个原型对应候选的一个分布)。然后,我们通过下面的公式计算原型值$\mathbf{v^p}$:
$$
\mathbf{v^p=v^c W(k^c,k^p)}
$$
最后,$\mathbf{k^p}$和$\mathbf{v^p}$被分别添加到长时记忆$\mathbf{k^{lt}}$和$\mathbf{v^{lt}}$中,从而完成记忆整合过程。注意,相似的原型逼近也被用于transformer模型中[^55][^38]。不同的是,我们的方法使用了一种适用于视频对象分割的新型原型选择方案。
移除过时特征
虽然长时记忆紧凑性高(压缩率$>6000%$),但是不断添加新的特征也会造成内存的溢出。根据经验,6GB的内存空间(如:中等消费级GPU)可以处理34000帧。为了处理更长的视频,我们引入了最小频率使用算法[^29],区别在于我们的“使用”(Sec3.3中定义的原型选择)是由top-k滤波[^8]后的累积关联定义的,这样的滤波避免了引入额外的阈值超参数。当超过了预定义的内存使用限制时,使用频率最低的长时记忆元素将会被剔除。
长时记忆是保证长时视频精准有效分割的关键。接下来,我们将讨论工作记忆,这个是精准地短时预测的关键,并且学是长时记忆的基础。
Sec3.4 工作记忆(Working Memory)
工作记忆将高分辨率特征存储在临时缓冲区中,有助于在几秒钟的时间范围内进行准确地匹配,还充当了长时记忆的网关,因为每个记忆元素的重要性是通过它们在工作记忆中的使用频率进行估计的。
在我们的多存储特征记忆设计中,工作记忆的经典的实例化已经足够得到好的结果,大幅度地使用STCN风格[^9]的特征记忆库(基线)作为我们的工作记忆。为了全文完整性,我们将会给出简要地说明,详情请参考[^9]。注意,我们的记忆读取步骤(Sec3.2)与[^9]仍然存在显著不同。工作记忆由键$\mathbf{k^w}\in\mathbb{R}^{C^k\times THW}$和值$\mathbf{v^w}\in\mathbb{R}^{C^v\times THW}$组成,其中$T$为工作记忆帧的数目。键是从图像中编码得到的,并且与查询$\mathbf{q}$位于相同的嵌入空间中;而值是从图像和掩膜中编码得到的。图3右下角描述了工作记忆更新过程。在每$r$帧中,第一步复制查询为新的键;第二步输入图像和预测掩膜到值编码器中生成新的值。新的键与值添加到工作记忆中,供后续的帧通过记忆读取来使用。为了避免内存爆炸,我们通过将额外的帧合并到长时记存储中来限制工作记忆中的帧的数目$T:T_\min\leq T<T_\max$(详见Sec3.3)。
Sec3.5 感官记忆(Sensory Memory)
感官记忆专注于短时,并且保留了低层级的信息(如:对象位置),这样就很好地补充了工作记忆与长时记忆中空间位置信息的缺失。与工作记忆类似,我们也找到了一个能够很好地工作的经典基线。
具体来说,感官记忆存储一个隐式的表示$\mathbf{h_t}\in\mathbb{R}^{C^h\times H\times W}$,初始化为零向量,并且通过门控递归单元(Gated Recurrent Unit,GRU)[^11]实现传播(参见图6)。这个感官记忆每帧都使用解码器的多尺度特征实现更新。在每$r$帧,当一个新的工作记忆帧生成时,执行深度更新。从值编码器中获得的特征使用另一个GRU刷新感官记忆,使得感官记忆可以抛弃已经保存在工作记忆中的冗余信息,还能够在重用现有功能时,以最小的开销从深度网络(如:值编码器)中接收更新。
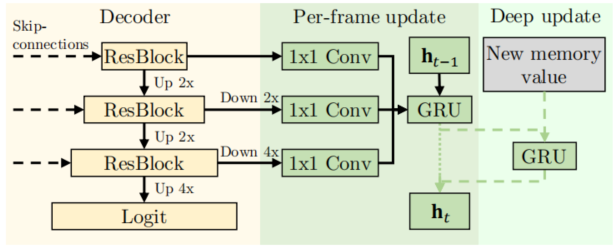
图6. 感官记忆更新预览。从解码器中得到的多尺度特征被下采样,然后作为输入拼接到GRU。在深度更新中,额外使用了一个单独的GRU来刷新感官记忆。
Sec3.6 实现细节
在这里,我们描述一些关键的实现细节。为了完全再现训练和推理,请参阅我们的开源实现。
网络
根据通常实践[^36][^43][^29][^9],我们采用ResNets[^17]作为特征提取器,移除了分类头和最后的卷积阶段,输出结果为步幅16的特征。查询编码器基于ResNet-50,值编码器基于RresNet-18,参见[^9]。为了生成查询$\mathbf{q}$、收缩项$\mathbf{s}$和选择项$\mathbf{e}$,我们将独立的$3\times3$卷积投影应用于查询编码器的特征输出。注意到查询和收缩项都用于当前的查询帧,而且当且仅当插入新的工作记忆时,选择项被复制到内存中(沿着图3的复制路径),以便未来使用。同样参考[^9]设置$C^k=64,C^v=512,C^h=64$。为了控制收缩因子的范围在$[1,\infin)$应用函数$(\cdot)^2+1$;为了控制选择因子的范围在$[0,1]$应用函数$\text{sigmoid}(\cdot)$。
解码器拼接隐式表示$\mathbf{h}_{t-1}$和读出特征$\mathbf{F}$。然后,它按照同一时间$2\times$速率迭代上采样直到步幅为4,同时根据STM[^36]在每个层级融合来自查询编码器的跳跃连接。步幅为4的特征图按照$3\times3$卷积投影到单通道的$\text{logit}(\cdot)$函数,再通过双线性上采样到输入分辨率。在多对象场景中,通过软聚合[^36]从不同的对象去融合最终的$\text{logits}(\cdot)$。注意,计算的主体(如:查询编码器、关联矩阵$\mathbf{W}$)可以在不同的对象之间共享,因为它们仅以图像为条件[^9]。
训练
在[^36][^43][^29][^9]之后,我们首先通过三个由变形的静态图像生成的合成序列上预训练网络。我们采用的是未经修改的STCN[^9]开源实现,这个代码也用于训练[^45][^51][^25][^62][^7]。接下来,我们使用课程采样[^36]在YouTubeVOS[^57]和DAVIS[^41]数据集上执行主要训练。我们注意到三的默认序列长度不足以训练感官记忆,因为它严重依赖于初始的状态。因此,我们转而对长度为8的序列进行采样。为了减少训练时间,并且进行正则化,随机选择最多三个(而不是所有)过去帧作为训练时间中任何查询的工作记忆。在两个RTX A6000 的GPU上整个训练过程大约需要35个小时。深度更新以0.2的概率执行,这个概率即$1/r$,$r=5$依据默认的参考[^9]。我们还在BL30K[^8][^12][^4]上进行预训练,从而进一步提高了准确性。我们使用星号标记任何使用BL30K的方法。
我们使用了自举交叉熵损失和骰子损失,其权重依据[^60]。为了优化需要,我们使用AdamW[^24][^30],其学习率为$1e-5$,权重衰减为$0.05$,在静态图像预训练中批次大小为16,迭代次数为150K,在主训练中批次大小为8,迭代次数为110K。在第一次80K迭代之后,我们将学习率降低了10倍。为了进行公平的比较,我们还使用上述设置重新训练了STCN[^9]基线。STCN的性能没有显著地差异(见附录)。
Ch04 实验结果
除非另有说明,我们使用$T_\min=5,T_\max=10,P=128$,从而导致从工作记忆到长时记忆的压缩比率为$6328%$。我们将长时记忆元素的最大数量设置为10000,这意味着XMem消耗的GPU内存不会超过1.4GB,从而有可能在移动设备上应用这个框架。我们使用$k=30$的top-k滤波[^8],480p的分辨率视频。为了进行评估,我们使用标准指标(越高越好)[^40]:Jaccard指数$\mathcal{J}$、轮廓精度$\mathcal{F}$和它们的均值$\mathcal{J}&\mathcal{F}$。对于YouTubeVOS[^57],分别为“可见”类(下标S)和“不可见”类(下标U)计算$\mathcal{J}$和$\mathcal{F}$,$\mathcal{G}$是可见类和不可见类的平均$\mathcal{J}&\mathcal{F}$。对于AOT[^60],我们与它们的R50变体进行了比较,因为变体与我们具有相同的ResNet骨架。
Sec4.4 局限性
当目标物体移动过快或者存在严重的运动模糊时,我们的方法有时会失败,这是因为即使是更新最快的感官记忆也无法跟踪变化(参见附录)。我们认为,具有比基线实例更大的感受野可能会有所帮助。
Ch05 结论
据我们所知,我们展示XMem是第一个用于视频对象分割的多存储特征记忆模型。XMem在长时视频和短时视频中都能以最小的GPU内存使用量实现出色的性能。我们相信XMem是在移动设备上满足VOS实用性的好的开始,也希望能够引起人们对长时VOS任务更多的关注。