网格分割网络:在三维牙齿曲面上深度多尺度网格特征学习用于端到端的牙齿标记
摘要
在计算机辅助正畸治疗计划中,对牙齿的三维曲面执行精确的标记是一项非常重要的任务。现有的自动化的或者半自动化的方法通常因为人工交互而非常耗时。此外,他们使用的典型操作是使用简单的几何性质作为分割的标准,这不能很好地处理不同患者之间外观的高度变化。最近,在计算机视觉社区和计算机图形社区已经提出了几种开创性的深度神经网络(如:PointNet),以端到端的方式有效地分割三维形状。然而,这些方法在我们的特定牙齿标记任务中表现不佳,特别是考虑到它们不能显式地建模牙齿的细粒度局部几何上下文(尽管只属于牙齿曲面的一小部分,但是拥有完全不同的形状的外观)。在本文中,我们提出了一个特定的深度神经网络(称为MeshSegNet),用于在先进的口腔扫描仪(IOS,口扫)捕获的三维牙齿曲面上进行端到端的牙齿分割。MeshSegNet直接使用原始网格数据作为输入,采用新颖的图约束学习模块去分层提取多尺度上下文特征,然后稠密地集成从局部到全局的几何特征来完整地描述网格单元用于分割任务。我们通过三重交叉验证在自己的临床数据集上评估了我们提出的方法。实验结果证明MeshSegNet方法在三维形状分割上与深度学习中SOTA方法相比具有更好的性能。
关键词
口腔扫描仪,深度神经网络,牙齿分割,网格,图约束学习模块,多尺度上下文特征
Sec01 介绍
作为用于正畸治疗计划的计算机辅助设计(CAD)系统的根本组件,从数字化的牙齿曲面模型执行精确地牙齿分割/分区是牙齿位置的分析与重排的前提[^4]。在正畸的临床实践中,三维口腔扫描仪(IOS,口扫)越来越广泛地应用于直接重建牙龈组织的数字化曲面模型[^5]。相比传统的物理印模,这种直接的数字印模对患者来说更加省时和舒适,避免了由物理印模材料中的许多成分引起过敏的潜在风险[^9]。在三维曲面上自动化地分割牙齿是一项具有挑战性的任务,主要考虑到不同实验对象(患者)的牙齿形状差异很大,并且患者的牙齿通常有异常外观(例如:相邻的牙齿存在拥挤和错位)[^12]。由于非牙齿部分(如:牙龈组织)通常具有明显不规则的形状,并且口腔的深度区域(如:第二或第三磨牙)可能无法被光源完美地照亮,因此在口扫(IOS)获得的原始牙齿曲面上,分割任务就变得极具挑战性。
用于自动化或者半自动化牙齿分割的传统方法通常将三维网格投影到二维图像上[^4]或者依据一些预先选择的几何性质直接分离三维网格[^14]。虽然这些想法是直接和直观的,但是大多数传统方法需要人消耗时间执行交互,并且它们的性能也很容易受到牙齿外观变化的影响[^12]。基于学习的形状分析或者几何分析已经在计算机视觉和计算机图形学领域得到了广泛的研究,这也是它们潜在地适用于牙齿分割这类特定任务的原因。例如:在[^12]中,手工制作的几何特征被预定义并重塑为图像,用于训练一个多级卷积神经网络(Convolutional Neural Network,CNN)来标记牙齿曲面的网格单元。然而,CNN的这种直接应用可能会导致不稳定的分割,因为它忽略了输入的几何特征是无序的这个事实,即输入的不同组合表示不同的“图像”。另一个潜在的限制是,这种多级CNN独立地执行不同的步骤,这可能会增加系统的复杂度,妨碍其在实践中的应用。最近,在端到端的三维分析上提出了一个开创性的工作PointNet。直接使用原始的几何数据(如:点云的坐标和法向量)作为输入,PointNet学习具有平移不变性的深度特征用于形状分类或者部件分割,从而在效率和准确性方法获得了SOTA的性能。原始的PointNet的主要局限性是忽略了局部的几何上下文信息,然而已经被证明有效地建模局部结构是深度神经网络在细粒度分割任务中成功的关键。虽然许多通过包含上下文信息扩展PointNet[^2][^6][^11]的努力已经被提出,但是他们通常根据点的空间关系将点粗略地分组到几个簇中。这种粗略地操作在细粒度牙齿分割这类特定任务上表现不好,特别是考虑到每颗牙齿只占据了整个牙体曲面的非常小的一部分。
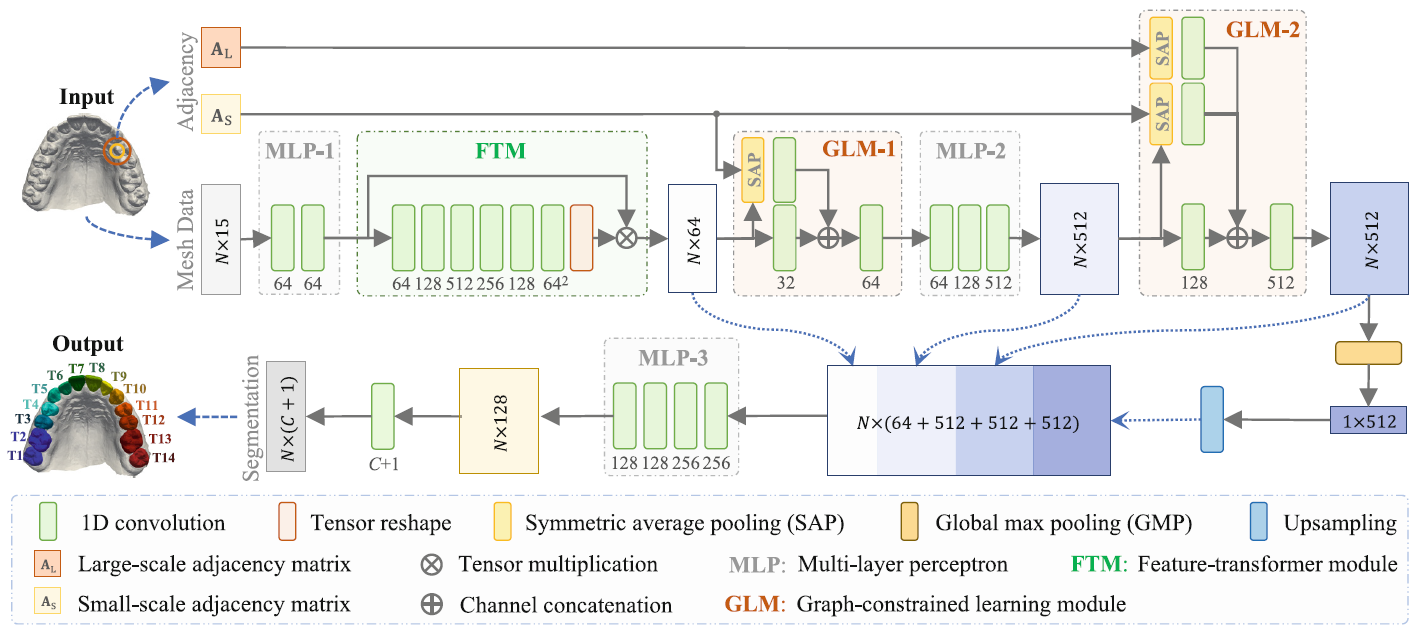
图1:MeshSegNet模型的示意图,一个多尺度深度神经网络,用于学习高级的几何特征,用于在三维牙齿曲面上进行端到端的牙齿分割。
在本文中,我们提出了一种端到端的深度神经网络(MeshSegNet),直接地从原始牙齿网格数据中学习高级几何特征用于自动化地牙齿分割(详见图1)。具体来说,MeshSegNet从三个方面扩展了SOTA的PointNet:
- 使用网格单元代替点作为输入,因为网格单元自然地联合了拓扑链接的点来清晰地显示局部结构[^1];
- 提出了多尺度图约束学习模块,从而显式地建模局部几何上下文,模拟CNN的层次特征学习过程;
- 稠密地整合了单元方面的特征、多尺度上下文特征和具有平移不变性的整体特征用于单元标注。
Sec02 方法
输入
MeshSegNet的输入$\mathbf{F}^0$是尺寸为$N\times15$原始的网格曲面数据,其中$N$是网格单元的数目。每个单元最初由$15$维输入描述。具体而言,每个单元由三个顶点坐标(9个单位)和法向量(3个单位)及提供补充信息的这个单元相对于整个曲面的相对位置(3个单位)组成。
MeshSegNet架构
如图1所示,MeshSegNet遵循PointNet的架构,使用连续的多层感知机(Multi-Layer Perceptron,MLP)来提取更高层次的几何特征。类似于CNN中的卷积层,网络中每个MLP的可以学习的参数在所有的输入网格单元中共享。此外,与[^7]一致,MeshSegNet的第一个MLP(即:MLP-1)紧接在特征变换模块(Feature-Transformer Module,FTM)之后,FTM将所有的输入映射到一个规范的特征空间中,以提高学习到的特征表示关于输入曲面的潜在的几何变换的稳健性。将MLP-1学习得到的特征描述为$\mathbf{F}^1\in\mathbb{R}^{N\times64}$。FTM从$\mathbf{F}^1$预测了一个变换矩阵$\mathbf{T}\in\mathbb{R}^{64\times64}$,直接将特征矩阵更新为$\hat{\mathbf{F}}^1=\mathbf{F}^1\mathbf{T}$。与原始的PointNet架构相比,MeshSegNet的主要创新包括:
- 多尺度局部几何特征的图约束分层学习;
- 从局部到全局特征的稠密融合用于分割任务
(1)多尺度图约束学习
我们提出了一个图约束学习模块(Graph-Constrained Learning Module,GLM)来显式地捕捉输入曲面的局部几何上下文。GLM(即GLM-1和GLM-2)沿着MeshSegNet的前向路径(即在FTM和MLP-2之后)在不同阶段被整合,其模仿CNN渐近地增加感受野用于学习分层多尺度上下文特征。具体来说,将三维网格的每个单元都看作质心,使用两个不同的半径定义它的邻域球,得到的$N\times N$的邻接矩阵(即分别用于小球的$\mathbf{A}_S$和大球的$\mathbf{A}_L$)描述在潜在的欧几里德空间的任意两个单元的图链接。基于$\mathbf{A}_S$,MeshSegNet的GLM-1首先在$\hat{\mathbf{F}}^1$(即FTM的输出)上应用基于图的融合操作(称为对称平均池,Symmetric Average Pooling,SAP),以将上下文信息(由相邻单元提供)传播到每一个质心单元中。最终的特征矩阵$\tilde{\mathbf{F}}^1\in\mathbb{R}^{N\times64}$编码了局部几何上下文,形式如下:
$$
\tilde{\mathbf{F}}^1=
(\tilde{\mathbf{D}}_S^{-\frac12}
\tilde{\mathbf{A}}_S
\tilde{\mathbf{D}}_S^{-\frac12})
\hat{\mathbf{F}}^1
$$
其中,$\tilde{\mathbf{A}}_S=\mathbf{A}_S+\mathbf{I}$可以看作自环的邻接,$\tilde{\mathbf{D}}_S^{-\frac12}\tilde{\mathbf{A}}_S\tilde{\mathbf{D}}_S^{-\frac12}$ 是各自的对称归一化链接,$\tilde{\mathbf{D}}_S$是对角化的度矩阵。在对称平均池(SAP)之后,$\tilde{\mathbf{F}}^1$与$\hat{\mathbf{F}}^1$都被拥有32通道的一维共享权重的卷积层执行压缩,再将输出的特征矩阵跨通道拼接,然后再由一个64通道的一维卷积层执行融合。请注意,GLM的完整操作在某种意义上是图卷积网络[^3]的扩展,即:GLM-1的输出$\mathbf{F}^{S1}$的形式如下:
$$
\mathbf{F}^{S1}=\sigma({
\sigma(\hat{\mathbf{F}}^1\mathbf{W}^1)\oplus
\sigma(\tilde{\mathbf{F}}^1\mathbf{W}^1)}
\mathbf{W}^2)
$$
其中,$\sigma(\hat{\mathbf{F}}^1\mathbf{W}^1)$与图卷积层[^3]相似,$\sigma(\cdot)$是ReLU激活函数,$\oplus$表示逐个通道的拼接,$\mathbf{W}^1$和$\mathbf{W}^2$分别是32通道和64通道的一维卷积层的可以学习的权重。
与GLM-1不同,GLM-2扩大了感受野,学习了多尺度上下文特征。具体来说,基于等式(1),来自于MLP-2(即:$\mathbf{F}^2$)的$N\times512$的特征矩阵分别通过两个并行的SAP($\mathbf{A}_S$和$\mathbf{A}_L$)进行处理。然后,产生的特征矩阵和$\mathbf{F}^2$通过128通道的一维共享权重的卷积层执行压缩,最终这些通道完成跨通道的拼接,并且使用另一个具有512通道的一维卷积层执行融合。请注意,虽然在我们当前的实现中使用了两个GLM,但是作为一个通用的架构,MeshSegNet可以沿着其前向路径集成更多的GLM,从而根据任务的需要学习更多尺度的上下文特征。
(2)局部到全局特征的稠密融合
沿着[^7]的思路,我们在GLM-2的输出上应用全局最大池化(Global Max Pooling,GMP)来产生平移不变的整体特征,旨在编码整个牙齿曲面的语义信息。与PointNet不同的是,PointNet只在整体特征与单元特征或者点特征之间插入了跳跃连接,而MeshSegNet假设了多尺度上下文特征(由中间的GLM生成)可以提供附加的信息来全面地描述网格单元。相应地,MeshSegNet稠密地拼接了来自FTM、GLM-1、GLM-2和(上采样的)GMP的从局部到全局的特征,然后紧接着MLP-3以产生一个$N\times128$特征矩阵。基于这个矩阵,应用一个带 softmax 激活函数的一维卷积层预测$N\times(C+1)$的概率矩阵,矩阵的每一行分别描述网格单元属于特定类别(即:牙龈与$C$种类别的牙齿)的概率。
实现与数据增强
如图1所示,MeshSegNet模型包括:
- 三个MLP(即:MLP-1、MLP-2、MLP-3)
- MLP-1:包括两个一维卷积层,通道数为(64,64)
- MLP-2:包括三个一维卷积层,通道数为(64,128,512)
- MLP-3:包括四个一维卷积层,通道数为(256,256,128,128)
- 注:一维卷积层都使用批处理归一化(Batch Normalization,BN)和ReLU激活函数。
- 一个FTM:包括六个一维卷积层,通道数为(64,128,512,256,128,$64^2$)。用于学习MLP-1的输出$\mathbf{F}^1$的特征变换矩阵$\mathbf{T}\in\mathbb{R}^{64\times64}$,
- 注:前面五层的每一层后面都是BN和ReLU,最后一层(没有BN和ReLU)后面是张量变维操作。
- 二个GLM(即:GLM-1、GLM-2)
- 注:一维卷积层都使用批处理归一化(Batch Normalization,BN)和ReLU激活函数。
- 一个最终的一维卷积层,用于输出softmax分割概率。
MeshSegNet的Python实现是基于Keras。通过最小化广义骰子(Dice)损失[^10]进行训练,训练时使用Adam优化器的AMSGrad变体[^8](小批量:10;迭代周期:200)。为了提升训练网络的泛化能力,我们在合理的的范围内结合了:(1)随机旋转;(2)随机平移;(3)随机缩放(如:放大/缩小)对训练集和验证集的对每一个三维曲面进行了数据增强。在那之后,在每一个训练/验证曲面(大约1万个单元)对每一颗牙齿进行随机采样$50%$,然后从牙龈中随机采样剩余的单元作为网络的输入(总共有6千个单元)。请注意,所有上述操作的组合可以大幅度地丰富训练集,并且还缓解了不平衡的学习挑战,这种不平衡是由于每颗牙齿只能提取整个牙体曲面非常小的一部分数据。在网络训练后,我们直接将训练好的网络应用到未见过的测试曲面去预测对应的分割。也就是说,与训练阶段相比,我们的网络可以直接在测试阶段直接处理不同尺寸的完整的牙体曲面,这在实践中具有实际的意义。
Sec03 实验
数据集和实验设置
本文研究的原始数据集包含了20个不同受试者的上颌牙体曲面,数据通过内部三维IOS采集。原始曲面大致包含10万个网格单元,在保留原始拓扑的同时,这些网格单元被下采样到1万个单元。基准分割是$C=14$颗牙齿类别(即左右两侧从中切牙到第二磨牙)已经由牙科住院医生(有经验的牙齿指导下)在下采样曲面上执行了手工标注。
我们对这个数据集执行了3重交叉验证。在每次迭代中,从训练集中随机选择一个曲面进行验证,然后使用Sec02中描述的数据增强协议通过为每个曲面模拟100个“新”的曲面来扩大训练集与验证集。训练/验证集的输入(维度:$6000\times15$)实时地在每个曲面上随机采样。使用相同的实验设置、损失函数和优化器,我们比较了MeshSegNet和当下最先进的PointNet[^7]。为了更加全面的评估,我们还设计了一个PointNet的稠密变体(称为PointNet-D),其中中间特征与网格方向的特征和整体的特征进行拼接用于分割任务。为了验证MeshSegNet的基础组件(即:多尺度图约束学习和局部到全局的稠密融合)的有效性,我们还比较了MeshSegNet及其两个变体(即:MeshSegNet-S与MeshSegNet-F)。在MeshSegNet-S中,与$\mathbf{A}_L$相关的SAP和卷积层从GLM-2中移除,并且单独的网络仅能执行单尺度局部上下文建模。在MeshSegNet-F中,通过移除GLM-1和GLM-2的连接,我们仅为MLP-3融合了网格方向的特征和整体的特征。基于基准标注,通过三个指标,即:骰子相似度系数(Dice Similarity Coefficient,DSC)、敏感度(Sensitivity,SEN)和正预测值(Positive Prediction Value,PPV),对分割的结果进行定理地评估。
结果
表1:在三重交叉验证下量化的所有牙齿的分割结果($均值\pm标准差$),其中$p$指示了我们的MeshSegNet方法和每种竞争性方法之间用于统计指标显著性比较的$p$-值

根据这三个指标,所有牙齿的整体分割结果汇总在表1中,并且每个牙齿的具体分割结果详见图2。从表1中,我们可以拥有至少三个观察:
- 与SOTA PointNet方法比较,我们的MeshSegNet和它的两个变体(即:MeshSegNet-S和MeshSegNet-F)获得了明显是更好的结果。实验结果表明,该方法能够有效地捕捉和利用局部几何上下文去改善分割性能。
- 我们的MeshSegNet在所有的度量方面都显著地优于其变体,考虑到网格单元的密度可能在不同的曲面和/或不同的位置上变化,这意味着对于牙体曲面上的牙齿分割需要显式地学习多尺度上下文特征。
- MeshSegNet也比它的变体MeshSegNet-F性能更好。这个说明,相比仅仅使用局部和全局特征的方法,局部和全局特征的稠密融合(即:单元方面、多尺度上下文和整体)可以为更加精确地分割带来额外的信息。通过比较PointNet-D和PointNet,可以看出稠密融合策略也提高了原始PointNet方法的性能。
每颗牙齿的分割结果如图2所示,与表1中总结的总体分割结果保持了一致。从图2中,我们可以看到MeshSegNet相比其他竞争方法在所有的牙齿上(即:从1号牙到14号牙)产生了更好的DSC值,而其变体(即:MeshSegNet-S和MeshSegNet-F)在大多数牙齿上也超越了当前最先进的PointNet及其变体(即:PointNet-D)。这些结果进一步验证了我们提出的方法在三维牙体曲面执行自动化牙齿分割任务上的有效性。值得注意的是,另一方面,相比PointNet,由MeshSegNet带来的改进对于磨牙(如:1号牙和14号牙)的分割更加显著。例如:MeshSegNet对于分割1号牙将DSC从0.711提高到0.900($\text{p-值}<1e-4$),将PPV从0.575提高到0.867($\text{p-值}<1e-6$)。请注意,分割磨牙是一项非常具有挑战性的任务,因为它们位于口腔的深处,并且可能不会被光源完全捕获。这些结果进一步表明了我们提出的方法的稳健性。
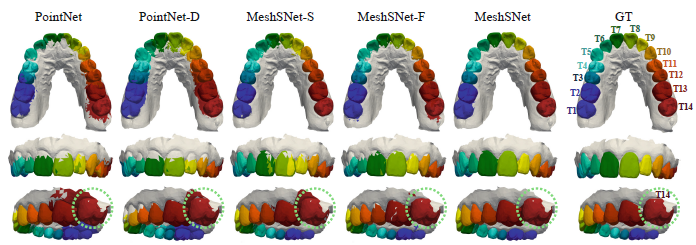
图3:三种代表性案例通过五种不同的方法产生的分割和基准(Ground-Truth,GT)标注。
在图3中,我们直观地比较了三个代表性案例的自动化分割和基准标注。从图3中,我们可以观察到MeshSegNet方法相比其他竞争方法拥有更好的整体性能。例如:相比PointNet和PointNet-D,MeshSegNet有效地减少了分割磨牙中的假阳性案例(见图3中第一行),并且还减少了分割中切牙中的假阴性案例(见图3中第二行)。特别的是,MeshSegNet方法可以更加精确地标注没有被IOS完全捕获的磨牙,这可以在图3中第三行的绿色圆圈中观察到。图3中的视觉评估与表1和图2中的定量评估表明MeshSegNet方法在实战中对牙体曲面的自动化牙齿标记具有潜在的价值。
Sec04 结论
在本文中,我们提出了一个深度神经网络(MeshSegNet),在通过先进的口腔扫描仪获得的原始牙体曲面上执行端到端的三维牙齿分割。MeshSegNet方法集成了新颖的图约束学习模块,在网格曲面上显式地建模多尺度局部几何上下文,然后使用稠密融合策略有效地组合局部到全局的特征,对网格单元进行综合性的描述。在内部临床数据集上实验结果表明,与最先进的用于三维形状分割的深度学习方法相比,我们提出的方法具有更好的性能。作为未来的工作,我们尝试集成可以训练的后处理模块(如:基于条件随机场[^13])到我们当前的模型中去进一步平滑分割的结果,即:避免独立的假阳性。此外,我们提出的方法应该在更多的主题上进行评估,以进一步验证其泛化能力。